What is the Learning Unit about?
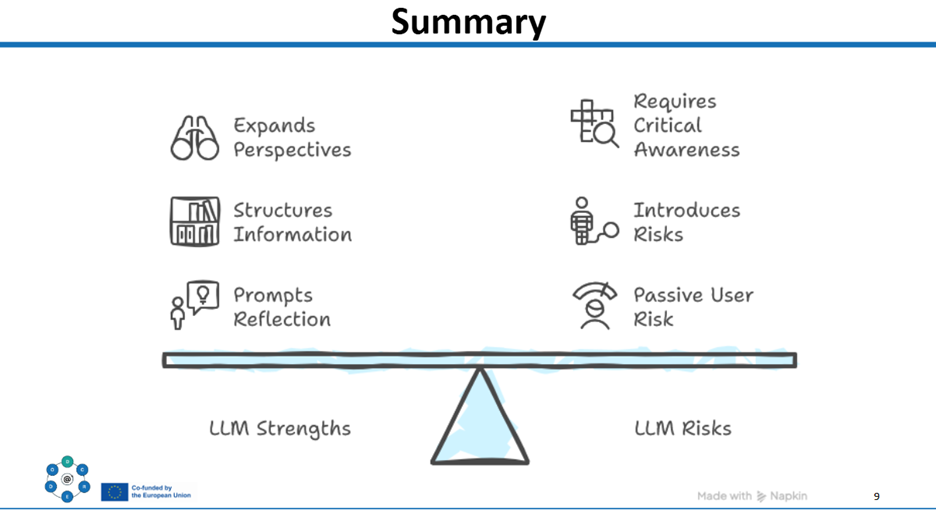
The unit is aimed at the more intermediate medical and nursing students. The core idea is simple: LLMs can be useful thinking partners, but they can also nudge people into cognitive traps (especially when the output sounds fluent and confident). So LU102 focuses on building habits that keep reasoning human-led: asking better questions, spotting bias, verifying outputs, and making deliberate decisions about what to trust and what to challenge. We intentionally do not prescribe a single LLM. Learners can use their preferred tool (e.g., ChatGPT, Copilot, institutional tools, etc.), because the unit is designed around transferable process skills rather than tool-specific features.
How We Developed It!
1) We designed the structure before we designed the “content.”
The main design decision was to let the structure and elements carry the learning goals:
- a clear progression in Moodle,
- an individual activity where learners work with an LLM in a guided way, and
- a synchronous in-class activity that makes bias and responsibility visible through discussion and comparison.
That structure helped us avoid a common failure mode when teaching emerging tech: turning the unit into a tool demo, rather than a learning experience.
2) We built around a learner journey
The learning journey is staged on purpose. First, an asynchronous preparation phase (about 90 minutes) introduces examples, bias awareness, and prompting in a clinical context, then asks students to do a guided LLM-supported reasoning task. Next, a 90-minute in-class session turns individual experiences into shared analysis: where did the model sound confident without evidence, what assumptions did it smuggle in, how did different prompts change conclusions, and what did verification do to the final answer? The assessment is reflective, because we want students to explicitly connect this to professional accountability: “I used the tool, I checked it, and I own the decision.”
3) Collaboration: shared ownership with a strong spine.
The team worked with Jonas as team lead, and contributors responsible for their own parts while keeping an eye on the overall coherence and progression. We collaborated primarily in Google Docs, with many team meetings to keep decisions aligned across content, learning design, and practical constraints. Coordination was straightforward and worked well: bi-weekly meetings, email communication in between, and clear task assignments.

4) The key “content” decision: density is the enemy of learning.
What was difficult?
- Making it less dense. We had a lot of good material. examples, angles, and “interesting extras.” The hardest design work was repeatedly asking:
What is essential for safe use, and what is optional enrichment? That prioritization shaped what stayed, what got shortened, and what was moved into optional directions rather than core pathway - Time pressure. The development period overlapped with the Christmas holiday, which made time and availability a real constraint. We managed it by keeping tasks explicit and maintaining a reliable cadence for decisions, but it definitely raised the stakes of prioritization.
There’s a deeper lesson hiding in these difficulties: LU102 is about not outsourcing your responsibility, and the development process mirrored that. We couldn’t “solve” the unit by collecting more content; we had to make intentional decisions about what mattered most and accept trade-offs.
A concrete example from LU102
In the individual activity, learners use their own chosen LLM to support clinical reasoning (for example, generating or refining a differential diagnosis). They are guided to formulate prompts deliberately and to pay attention not only to what the model answers, but to how it might be influencing their thinking. The point isn’t to get the “best” list of diagnoses, it’s to practice staying in charge: checking assumptions, asking for reasoning, and identifying uncertainty. In the synchronous session, learners bring insights (and sometimes contradictions) into a structured discussion: where did the model anchor them, where did it overgeneralize, where did it sound confident without justification, and how did verification change their conclusions? This makes the invisible part of LLM use, its pull on judgment, visible and discussable.
Stay connected with D-CREDO and follow our journey on LinkedIn for more updates, insights, and stories.